

Teaching & Research
Research Overview
Database System in the AI era
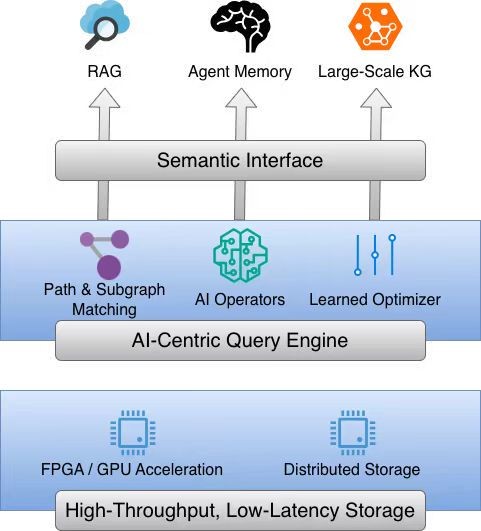
As artificial intelligence technologies continue to advance in depth, the application demands of data management are undergoing a profound paradigm shift—from traditional transaction processing toward a stronger emphasis on complex semantic relationships among entities. In this context, graph databases, with their natural topological advantages in modeling highly interconnected data, have become a critical foundation for core AI applications such as Retrieval-Augmented Generation (RAG), Agent Memory, and large-scale knowledge graphs. However, traditional database architectures struggle to meet the new challenges of the AI era. These challenges primarily manifest in the semantic interaction gap between AI models and database schemas, the lack of native support for semantic operators at the kernel level and the difficulty of incorporating them into the full query optimization pipeline, as well as severe performance bottlenecks in storage and query processing when handling extremely large-scale data.
To address these challenges, this research aims to build a next-generation graph database system deeply integrated with AI technologies. We will first design an AI-oriented semantic layer to eliminate barriers between data representation and model understanding. At the core query processing and optimization layer, we propose a novel unified optimization framework that supports flexible query definitions combining path traversal and subgraph matching. By embedding AI operators directly into the execution engine and integrating traditional rule-based optimization with cutting-edge learned optimizers, the framework seeks to achieve a qualitative leap in query efficiency. At the infrastructure level, the system will be built upon a distributed storage engine and a co-designed software–hardware architecture to ensure high throughput and low latency when processing massive datasets. Ultimately, this work aims to provide a robust and efficient data foundation for intelligent applications in the AI era.
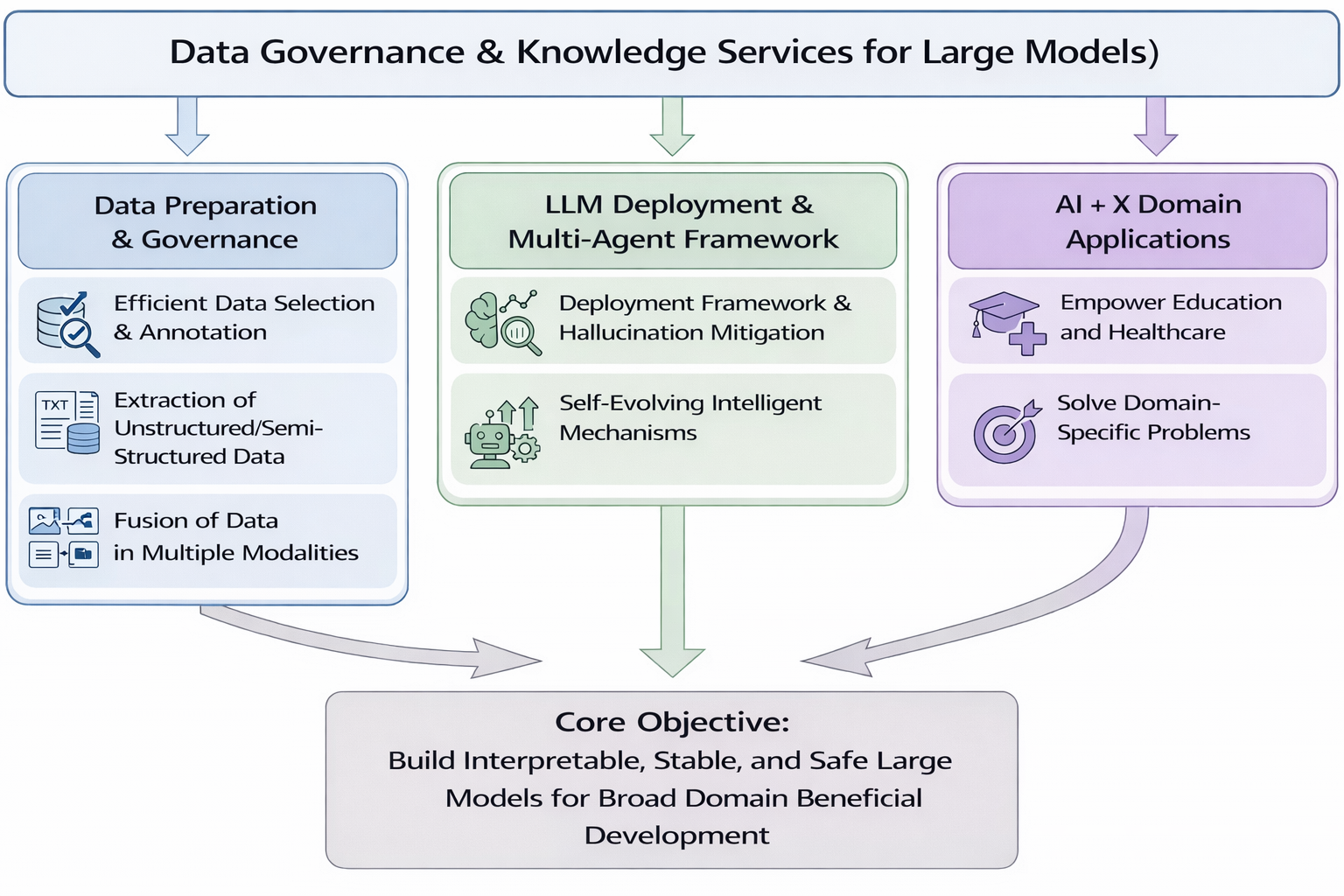
Data Governance and Services for Large Language Models
In recent years, the data-driven paradigm dominates large model research. The construction and deployment of large models involve massive volumes of data, which pose significant challenges, including high annotation costs, difficulties in managing unstructured and multimodal data, and concerns regarding the trustworthiness, robustness, fairness, and inclusiveness of real-world deployment. We aim to jointly optimize data governance quality and AI infrastructure efficiency to build interpretable, robust, and secure large-model inference mechanisms, thereby enabling deep empowerment and inclusive development of domain-specific intelligent applications. Specifically, our research includes the following directions:
Data Preparation and Governance: For AI-oriented data preparation, we focus on how to more efficiently select representative data for annotation, reducing labeling costs while improving annotation quality. In structured data extraction, we focus on developing advanced techniques to accurately extract valuable information from massive unstructured and semi-structured data and transform it into structured formats, providing high-quality data support for large model training. In multimodal data alignment, we investigate effective alignment and fusion methods across different modalities, leveraging the complementarity of multimodal information to enhance large models’ perception and comprehension capabilities.
LLM Inference and Multi-Agent Frameworks: To address the demand for interpretable inference, we conduct research on inference frameworks as well as hallucination detection and mitigation techniques. By deeply analyzing the reasoning processes of large models, we construct internal reasoning graphs to clearly present inference paths. Meanwhile, we employ advanced algorithms and technical approaches to accurately detect and eliminate hallucinations, improving the reliability and interpretability of large model inference. Furthermore, to enhance adaptability and self-evolution capabilities, we explore self-evolving agent mechanisms, incorporating bottom-up planning strategies and long- and short-term memory mechanisms, enabling agents to continuously learn and optimize through interaction with their environments.
AI + X Domain Applications: Building upon our comprehensive research achievements in natural language processing and large models, and integrating foundational work in database systems and data governance, we apply large model technologies to vertical domains such as education and healthcare. By addressing domain-specific challenges (e.g., rare disease diagnosis and treatment), we aim to deliver deep empowerment and transformative impact across these fields.
Management of Streaming Data and Time Series Data
With the continuous advancement of the national manufacturing power, next-generation information systems—such as the Industrial Internet of Things (IIoT), smart cities, and smart healthcare—are being rapidly deployed. Massive sensing devices continuously generate high-frequency, multi-source, and heterogeneous streaming data. Streaming data is naturally organized along the temporal dimension and, after online processing and persistent storage, is accumulated into structured time-series data. Streaming data management and time-series data management represent two tightly connected stages within the same data lifecycle: the former focuses on real-time computation and incremental processing during data arrival, while the latter emphasizes structured organization, quality assurance, and analytical support after data persistence.
The “process-as-it-arrives” paradigm of streaming data makes it difficult to rely on traditional offline centralized analysis. Meanwhile, practical systems commonly adopt a hierarchical collaborative architecture spanning device, edge, and cloud layers, where different tiers exhibit significant differences in computational resources, storage capacity, and tolerable latency. Data is generated at the device layer, processed with low latency at the edge layer, and stored and analyzed at scale in the cloud, forming a continuous evolution from stream processing to time-series data management. In this context, how to achieve efficient stream processing under resource constraints and high concurrency, while ensuring the quality and usability of time-series data, has become a fundamental challenge for supporting intelligent applications.
Centered on the full lifecycle of streaming and time-series data, this research aims to establish an integrated technical framework of “streaming real-time computation – time-series data persistent storage – data provisioning for intelligent tasks.” In the streaming computation stage, we investigate stream data summarization and sampling algorithms, as well as optimization mechanisms for complex persistent queries. We particularly explore collaborative mechanisms between real-time processing and micro-batching under high update intensity, improving overall throughput while maintaining low-latency responses and ensuring consistent semantics under out-of-order data arrival.
In the time-series data persistence stage, we focus on efficient ingestion mechanisms, storage structure optimization, and data quality assurance. We systematically study write strategies for delayed and out-of-order data, anomaly detection and repair mechanisms, and compression and storage optimization methods for time-series data. Under dynamically changing task requirements and resource constraints, we aim to achieve an adaptive balance between data quality and processing cost.
Furthermore, in the data provisioning stage for intelligent tasks, we design multi-granularity feature extraction methods and multi-resolution multi-source time-series alignment mechanisms tailored for intelligent analytics. We develop task-driven and resource-aware materialized view selection and maintenance strategies to provide high-quality, schedulable, and evolvable data views for upper-layer intelligent analysis and decision-making systems.
Through this layered collaboration and capability progression, this research seeks to establish a comprehensive methodology for streaming and time-series data management and analytics across device–edge–cloud architectures, providing a solid data foundation for the stable operation of large-scale information systems and the continuous evolution of intelligent applications.
